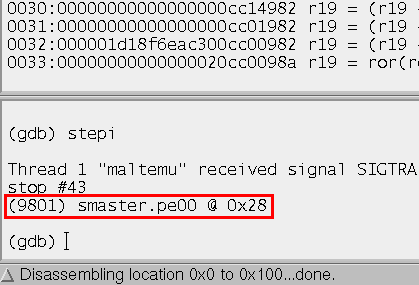
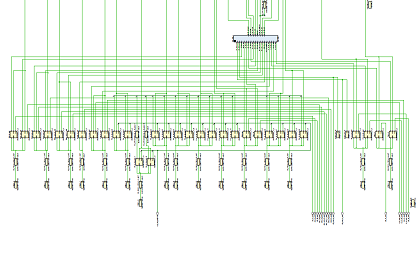
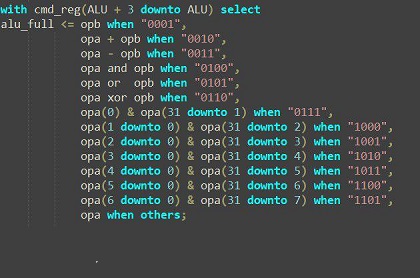
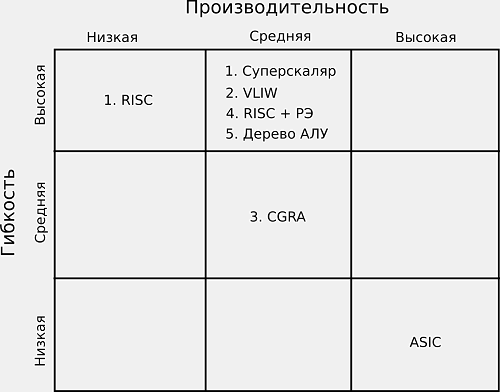
Завершено проектирование front-end 96-ядерного процессора MALT-Cv1
- Информация о материале
- Опубликовано: 18.01.2017, 20:00
 |
Фабрика TSMC Фото: TSMC |
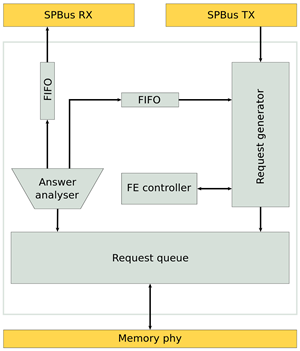
Завершено проектирование front-end процессора архитектуры MALT-Cv1 для изготовления СБИС в технологическом базисе 28 нм HPC+ компании TSMC (Тайвань). Данный базис предназначен для проектирования высокопроизводительных интегральных схем (high-performance computing, HPC). Разработанный процессор принадлежит к семейству MALT-C, содержит 9 RISC ядер общего назначения и 96 SIMD процессорных элементов. Оценочная площадь кристалла 12 мм2, энергопотребление 1,2 Вт на частоте 0,8 ГГц. Ориентировочная дата поступления образцов: январь 2018 года.